
Transformers
The transformer architecture, introduced in the landmark 2017 paper “Attention Is All You Need” by Vaswani et al., has fundamentally reshaped the field of artificial intelligence. By replacing recurrent and convolutional layers with a purely attention-based mechanism, transformers enable highly parallel computation and excel at capturing long-range dependencies in sequential data.
Transformers have become the backbone of modern natural language processing, computer vision, and even protein structure prediction. Their scalability and flexibility make them the architecture of choice for many of today’s most capable AI systems.
How Transformers Work
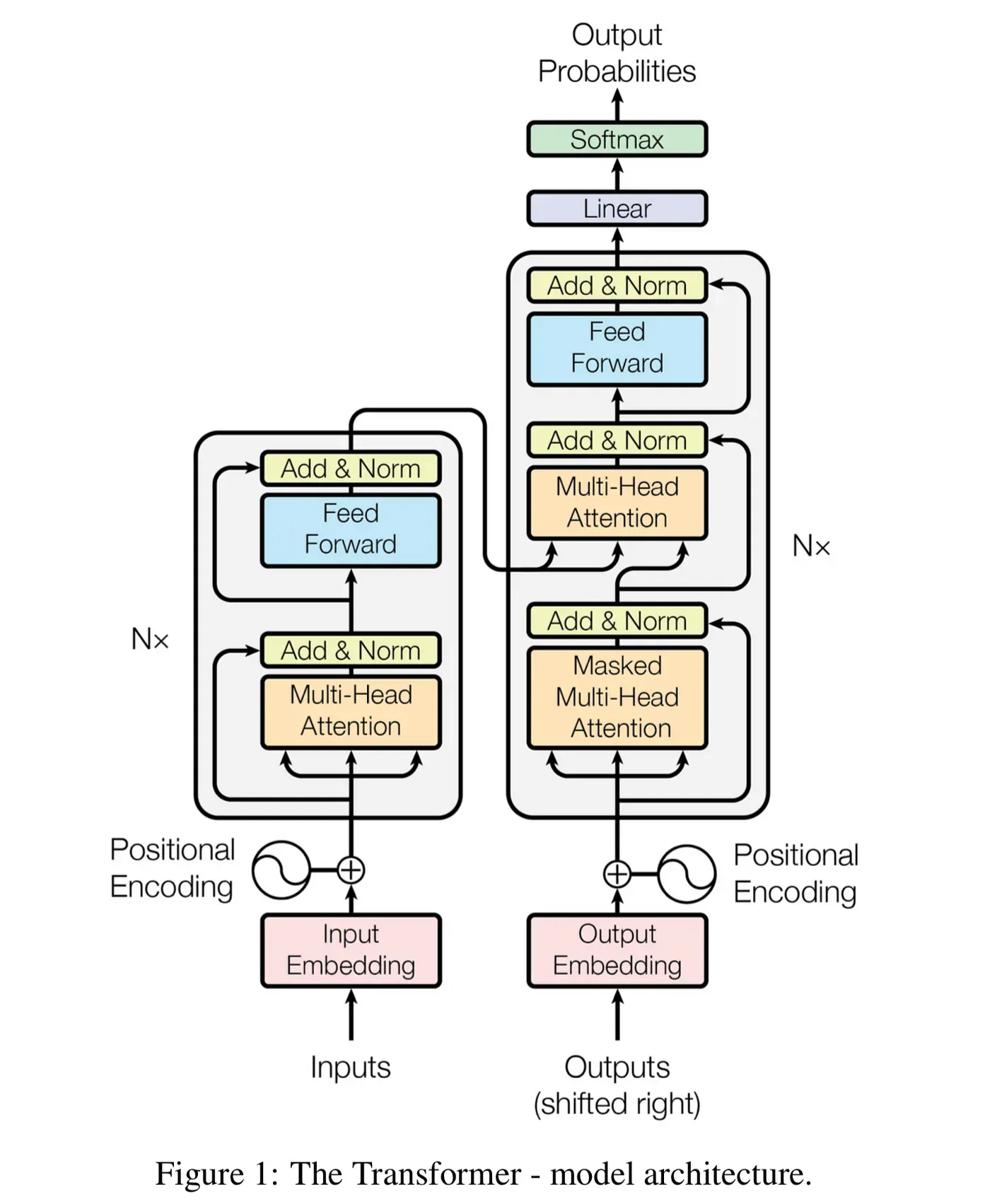
Section titled “How Transformers Work”At the core of the transformer is the self-attention mechanism, which allows each element in an input sequence to attend to every other element. This is computed through three learned linear projections — queries, keys, and values — that produce attention weights determining how much each element should influence others.
The architecture consists of an encoder and a decoder, each built from stacked layers of multi-head self-attention and feed-forward networks. The encoder processes the input sequence, while the decoder generates the output sequence, attending to both its own previous outputs and the encoder’s representations.
Positional encoding is added to input embeddings to provide the model with information about the order of elements, since self-attention itself is permutation-invariant.
Key Concepts
Section titled “Key Concepts”- Self-Attention — A mechanism that computes a weighted sum of all positions in a sequence, where weights are determined by the similarity between query and key vectors.
- Multi-Head Attention — Running multiple attention operations in parallel with different learned projections, allowing the model to capture different types of relationships.
- Positional Encoding — Sinusoidal or learned embeddings added to input representations to encode sequence order.
- Layer Normalization — A normalization technique applied within each transformer layer to stabilize training.
- Residual Connections — Skip connections that add the input of each sub-layer to its output, enabling deeper networks.
Further Reading
Section titled “Further Reading”
Attention Is All You Need
Vaswani et al., 2017 — the original transformer paper
arxiv.org
The Illustrated Transformer
Jay Alammar's visual walkthrough of the transformer architecture
jalammar.github.io
BERT: Pre-training of Deep Bidirectional Transformers
Devlin et al., 2019 — BERT and the era of pre-trained language models
arxiv.org